
 ==========尽职的安静的分隔线===========
==========尽职的安静的分隔线===========
在实际工作中遇到下面一个问题:
有一个表,存有2000万数据。
主键为ID bigint(20) NOT NULL auto_increment
另有一字段time timestamp NOT NULL default CURRENT_TIMESTAMP
故事从这两个字段说起:
sql1需要从这个表中检索出来时间为2010-05-26 11:55:00之前并且id号大于20000的前10条数据
sql2需要从这个表中检索出来时间为2010-05-26 11:55:00之后并且id号大于20000的前10条数据
两条sql写出来大概是这样子的:
sql1:select * from table where time 20000 order by id limit 10;
sql2:select * from table where time >'2010-05-26 11:55:00' and id>20000 order by id limit 10;
并且已经知道表中的数据,在上面所示时间之前的数据要远远多于所示时间之后的数据。如图1所示: 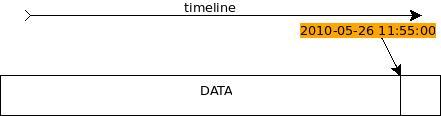 图1 数据在时间线上的示意图
图1 数据在时间线上的示意图
实测发现,sql1执行时间0.03s,sql2执行时间33s。
为何大于小于运行的速度相比如何巨大?下面来解答。
第一,用explain来观察两条sql的区别 结论:没什么区别
第二,研究order by 将sql2的order by id修改为order by id desc(排序方向颠倒)后,发现速度马上提到了0.03s的水平。
同样修改sql1的时候,速度马上降到了30s的水平。
进行多次测试,排除mysql本身的缓存干扰。
结论:
sql1的运行示意图如图2所示: 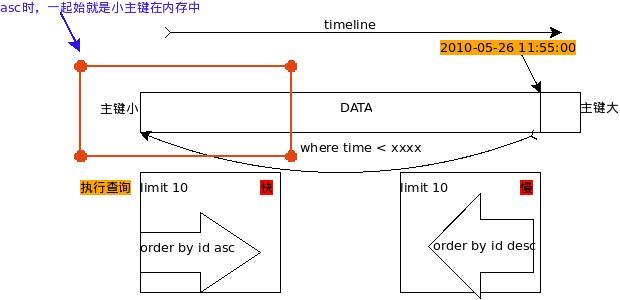 图2 第一条SQL语句快慢解释图
图2 第一条SQL语句快慢解释图
sql2的运行示意图如图3所示: 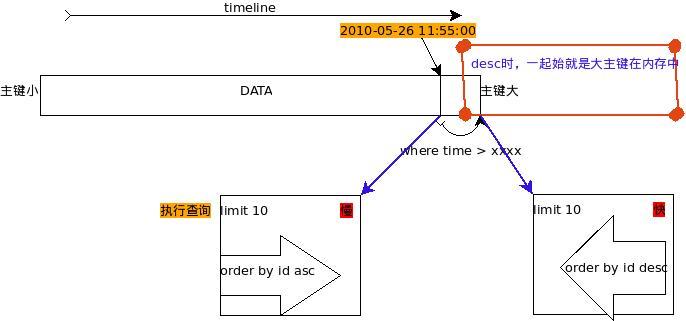 图2 第二条SQL语句快慢解释图
图2 第二条SQL语句快慢解释图
综合上面两个图,mySQL在where查询的时候,也许按照where的条件,按照主键的顺序,最后满足条件的,最后进到内存中去,再进行后面的order by时,asc如果在内存中比不在内存中的就要快得多。
未研究真正实现的代码,仅凭感觉验证。
一句话概括是:按照使用的索引,最后满足条件的数据将留在内存里供进一步排序。
原创文章如转载,请注明:转载自五四陈科学院[http://www.54chen.com]
Posted by 54chen 架构研究