

此文为《程序员》杂志约稿,发表在2010年9月刊。怀念过去美好的时光和所有的UGC兄弟真挚友谊,谨以此文为个人职业发展阶段作一个美好的终结。以下是全文原稿。
2009年8月左右,由于业务扩展的需要,我们的团队开始了一个新项目的研发,其中需要完成一个存储系统,把评论数据聚合到一起同时还要提供线上的读写服务。这些评论来自不同的业务产品,数据量非常之巨大;同时对稳定性的要求非常高,因为如果出现宕机,将影响到大量的业务线。于是,我们开始了对此类系统的探索。
Nuclear 的由来
经过需求分析阶段,摆在我们面前的是五点要求:高可用、高可扩展、高性能、Key-Value存储、支持关系化查询。经过一段痛苦的系统选型分析,我们最终决定开发属于人人网的海量存储系统。Nuclear,正如其名,nuclear的未来将要肩负起整个评论系统存储的核反应般的压力爆发的重任。由于当时并没有这方面的经验,一切都是摸着石头过河,我们设计了好几期的雏形,一开始明显就是有问题的构架设计,慢慢地在学习和进步的过程中,团队的成员也在慢慢地成长,离我们的目标也越来越近。又因为业务模型的需要和方便分布到集群,这个系统慢慢演变,最后成为了一个可靠的分布式key- value存储系统。以下特将在研发过程中遇到的问题做一个总结。
Key-Value系统的优缺点
NoSQL系统在过去的一两年里,饱受了争议和技术界的目光。从原理上讲,基本上这类系统都会有一些相同的优点和缺点:
优点:
1. 只有高效的查询可用,性能是可想像的。
2. 容易分布到集群。
3. 可以很容易增加缓存层用来加速读作。
4. 逻辑和存储清晰分离(出于性能考虑,关系型数据库鼓励将商业逻辑和存储作混在一起)。
缺点:
1. 没有复杂的查询过滤器。
2. 所有的联合查询必须在代码实现。
3. 没有外键的结构。
4. 没有触发器和视图。
Nuclear系统的一大特点是,我们改进了普通的key-value系统在存储模式上的固定形态,设计为上层的存储协议和底层的存储引擎完全分离,以便在不同的应用场景选择更合适的存储引擎。例如,当底层存储使用MySQL时,可以支持key→list结构的弱结构化读取;当底层存储只使用内存时,那无疑便是一个分布式缓存系统了。
高可用性
任意一个分布式的存储系统,都会遇到一个棘手的问题,那就是当一个数据节点出现故障的时候怎么办?是不是整个系统都跟着崩溃了?当然不行。是不是可以丢掉一部分数据呢?这也是不可接受的。这也是有不少网友经常反馈的一个问题。答案是唯一的,那就是不要把所有的鸡蛋都放在一个篮子里。但是如果一份数据在多个节点上有备份的话,那么这份数据的一致性也是一个致命的问题。
在参考了一些国内外分布式系统的处理方法后,我们归纳典型的做法有两种,一种是以亚马逊的dynamo系统为的NRW的方法;另一种是简单的主从备份使用心跳检测时刻检查节点是否故障的一种做法。
(1)亚马逊Dynamo的NRW
在Dynamo系统中,第一次提出来了NRW的方法。Dynamo系统是将数据复制多份的系统,靠以下的机制来保障节点故障时服务的正常提供:
N – 复制的次数
R – 读数据的最小节点数
W – 写成功的最小分区数
这三个数的具体作用呢,是用来灵活地调整Dynamo系统的可用性与复制数据一致性的。
举例来说,如果R=1的话,表示最少只需要去一个节点读数据即可,读到即返回,这时是可用性是很高的,但并不能保证数据的一致性,如果W同时为1的 话,那可用性更新是最高的一种情况,但这时完全不能保障数据的一致性,因为在可供复制的N个节点里,只需要写成功一次的话就返回了,也就意味着,有可能在读的这一次并没有真正读到需要的数据(一致性相当的不好)。理论上上我们可以做到N个节点中只要有一个节点正常,那么这次作就不会失败。如果 W=R=N=3的话,也就是说,每次写的时候,都保证所有要复制的点都写成功,读的时候也 是都读到,这样子一定读出来的数据是正确的,但是这中间的性能大打折扣,也就是说,数据的一致性非常的高,但系统的可用性却非常低了,有一个节点出故障了,这次作就失败了。如果R + W > N能够保证要读的数据肯定都是写成功的,Dynamo推荐使用322的组合使用可。
(2)常见的主从备份和心跳检测
主从备份最常见的要算是MySQL数据库的备份了,而如果做了主从备份的MySQL出现了故障的话,常规的做法也是即时检测与手机短信通知到人,然后再由工程师去手动处理,在工程师手动处理主从备份数据的过程中,MySQL靠log模式来保证数据的一致性。在诸如kata(apache下的一个分布式搜索)之类的系统中,由于在源码中使用了ZooKeeper这样的开发套件,在遇到分布式系统单点故障时,使得可以做到依靠系统本身也能全自动地进行节点的切换取舍,而这时数据的一致性,往往又需要另外的策略来保证。
以上两种方案,我们选择了第一种,原因主要是亚马逊的方法实现非常的简单,但是从理论上讲却非常的实用,真正有一种四两拨千斤的感觉,所以很多时候,好用的东西往往不是最难的,实用才是硬道理。
数据分布与迁移时遇到的压力冲击
Nuclear是一个分布式的key-value存储系统,key对应的数据分布在什么节点上,需要遵守一定的规则。在Nuclear中,数据分布在0~2^64的哈希环上,Nuclear集群初始化的时候,根据节点数均分整个哈希环。假如有A、B、C三个节点,key的分布如图1所示: 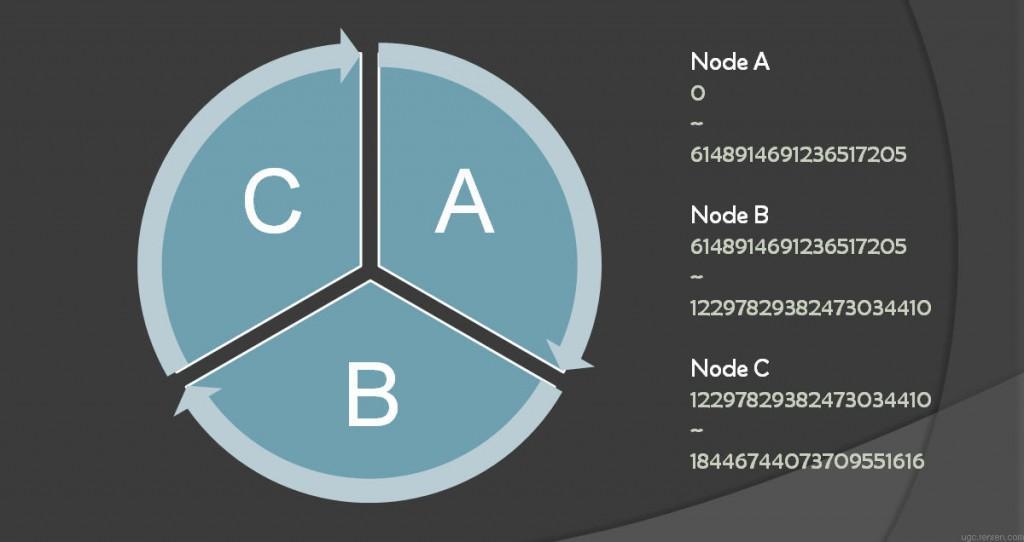 图1 key分布在三个节点的示意图
图1 key分布在三个节点的示意图
图1中,箭头方向表示复制的方向,假设N=3,表示复制三份,如图上的情况也就意味着每个节点都有三份数据,以此类推。
因为数据有多份,所以也存在着数据的自动迁移和恢复。这就会遇到一个问题:如果一个节点宕机后恢复,迁移程序势必需要以最快的速度将原来需要的数据通过网络从其他节点复制过来。这样的数据导出导入必然会对对应的节点造成一定的冲击,如果这时此节点开始提供服务,极有可能达到系统的临界点,反而将刚刚恢复的节点冲击宕机。
为了极力避开这样的情况发生,而且能快速地完成迁移的过程,在nuclear中,所有的数据迁移过程,都会提前判断作系统当前的负载情况,根据系统负载来暂停和重启迁移数据的线程。我们使用的开发语言是java,在JDK提供的java.lang.management包中,有许多监控系统负载的方法可以直接使用,非常方便。
系统架构和瓶颈分析
整个Nuclear系统构建于java之上,其系统架构如图2所示: 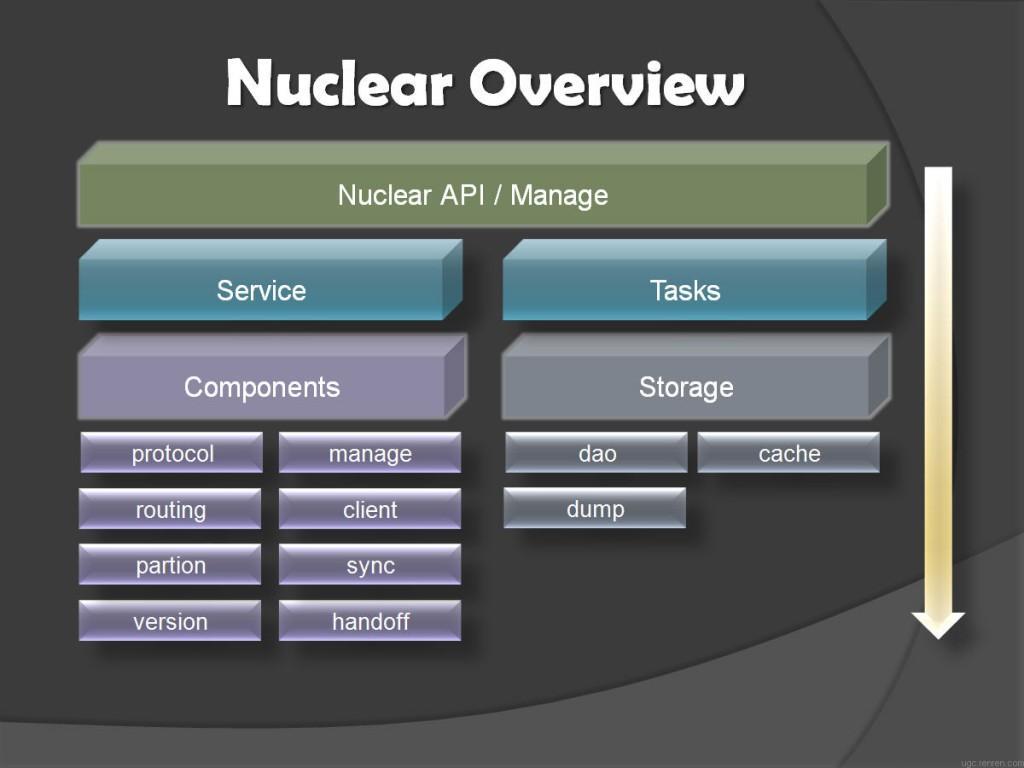 图2 Nuclear系统构架图
图2 Nuclear系统构架图
处在最上层的是对外的存储API,提供put、get等作,接下来一层分成了两个部分,一部分是正常的节点部分,一部分是后台运行的定时任务,下面都是组件化的模块,共同搭建了整个系统的稳定服务。
整个系统中最大的瓶颈出现在并发任务处理和数据传输上,为此我们大量使用了NIO、并发编程,充分发挥了多核CPU多线程处理的优势,尽量将网络传输导致延迟缩小到最小。这样做的结果是,在高并发的情况下系统中也不存在阻塞点,甚至可以说,Ncluear系统的设计哲学是:万事皆异步。
另一个更为直接的瓶颈,就是磁盘的IO瓶颈,在我们的实际线上环境中,最后遇到的问题也就是磁盘的瓶颈,在读写比为8比1且高并发压力的情况下,如果底层的存储引擎表现不佳,多半的原因都是,过多依赖了硬盘的读写,很容易就达到了硬盘IO的瓶颈,此时,我们的cache层的作用就举足轻重,将大多数的数据留在内存中,这是一个不错的做法。
 冷昊:人人网UGC团队成员,现和UGC技术团队一起为人人网用户在信息共享和传播的更加便捷做不懈努力,关注系统架构、分布式技术、数据挖掘。个人Blog: http://www.lenghao.com。可以通过电子邮件 jerome.leng@mail.com 联系到他。
冷昊:人人网UGC团队成员,现和UGC技术团队一起为人人网用户在信息共享和传播的更加便捷做不懈努力,关注系统架构、分布式技术、数据挖掘。个人Blog: http://www.lenghao.com。可以通过电子邮件 jerome.leng@mail.com 联系到他。  陈臻(54chen):人人网UGC团队成员,技术组织哥学社创始人,PHPChina内核版主,业余时间混迹于各技术组织且乐此不疲。个人Blog:http://www.54chen.com/ 。可以通过电子邮件 cc0cc@126.com 联系到他。
陈臻(54chen):人人网UGC团队成员,技术组织哥学社创始人,PHPChina内核版主,业余时间混迹于各技术组织且乐此不疲。个人Blog:http://www.54chen.com/ 。可以通过电子邮件 cc0cc@126.com 联系到他。
原创文章如转载,请注明:转载自五四陈科学院[http://www.54chen.com]